
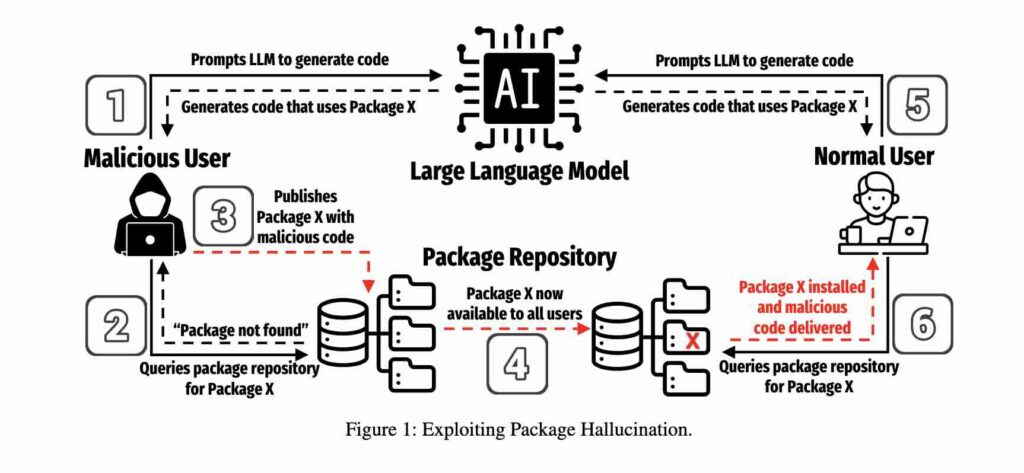
Grote taalmodellen ‘hallucineren’ nogal eens bij het programmeren en dat valt te misbruiken (afb: Joe Spracklen et al.)
Het onderzoek, waarbij zestien van de meest gebruikte grote taalmodellen werden gebruikt om 576 000 codevoorbeelden te genereren, toonde aan dat 440 000 van de pakketafhankelijkheden die ze bevatten ‘gehallucineerd’ waren, wat betekent dat ze niet bestonden. Open taalmodellen ‘hallucineerden’ het meest, met 21% van de afhankelijkheden die koppelden naar niet-bestaande bibliotheken.
Een afhankelijkheid is een essentieel codeonderdeel dat een apart stuk code nodig heeft om goed te kunnen werken. Afhankelijkheden besparen ontwikkelaars de moeite van het opnieuw schrijven van code en vormen een essentieel onderdeel van de moderne programmatuurtoeleveringsketen.
Deze niet-bestaande afhankelijkheden vormen een bedreiging voor de softwaretoeleveringsketen door zogenaamde afhankelijkheidsfoutaanvallen te verergeren. Deze aanvallen werken door een programma toegang te geven tot een foute componentafhankelijkheid die, bijvoorbeeld, kwaadaardig code publiceert en die dezelfde naam te geven als het legitieme pakket (een stuk code), maar met een stempel van een latere versie.
Deze vorm van aanval, ook bekend als pakketfout, werd voor het eerst gedemonstreerd in 2021 waarbij een namaakcode werd uitgevoerd op netwerken van enkele van de grootste bedrijven ter wereld. Het is een techniek die wordt gebruikt bij aanvallen op de programmatuurtoeleveringsketen, die erop gericht zijn om de code bij de bron te vergiftigen om zo alle gebruikers verderop in de keten te besmetten.
Voor het onderzoek voerden de onderzoekers dertig proeven uit, zestien in de programmeertaal Python en veertien in JavaScript. Deze tests genereerden 19 200 codevoorbeelden per test. Van de 2,23 miljoen pakketverwijzingen in deze voorbeelden, wees 19,7% naar pakketten die niet bestonden.
Meeste ‘hallucinaties’
Het gemiddelde percentage pakkethallucinaties dat werd veroorzaakt door open taalmodellen zoals CodeLlama (Meta) en DeepSeek bedroeg bijna 22%, vergeleken met iets meer dan 5% bij commerciële modellen. Code geschreven in Python resulteerde in minder hallucinaties dan JavaScript-code, met een gemiddelde van bijna 16%, vergeleken met iets meer dan 21% voor JavaScript.
De bevindingen zijn de meest recente die de inherente onbetrouwbaarheid van grote taalmodellen aantonen. Nu Kevin Scott van Microsoft voorspelt dat binnen vijf jaar 95% van de code door ki gegenereerd zal worden, valt te hopen dat er wat gedaan wordt aan die ‘onbetrouwbaarheid’ van ki.
Bron: Wired